開発者ブログ
Treasure Dataの開発チームによる技術記事、ベストプラクティス、エンジニアリングインサイト。

Treasure AI Night 開催レポート — AIネイティブプロダクトの裏側
Treasure AI Night の開催レポート。Treasure AIへのリブランディング、Treasure Workを支えるThree Layer Harness、エンタープライズAI基盤Treasure AI StudioとAI OS(AiOS)をご紹介します。
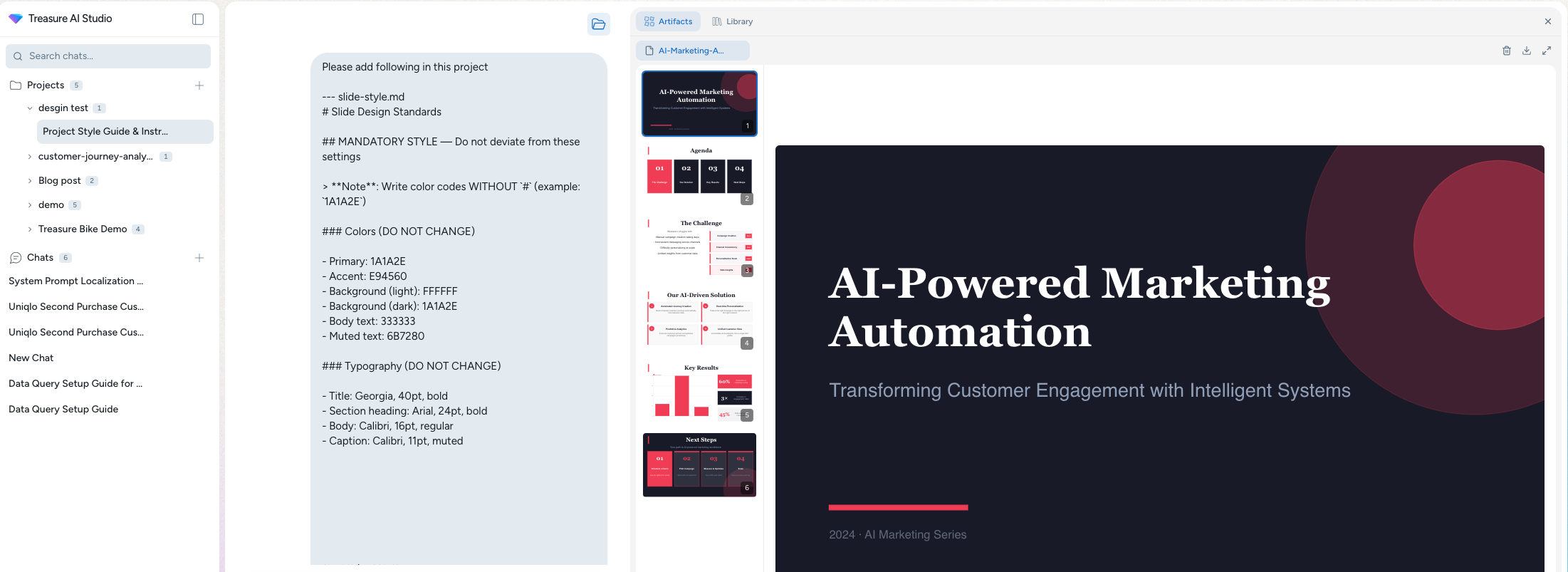
AIが生成するスライドのデザインを固定する方法 — slide-style.mdのすすめ
Treasure AI Studioでスライド生成のデザインを統一する実践的な方法。slide-style.mdを使った設定ファイル管理で、会話をまたいでも一貫したアウトプットを実現します。
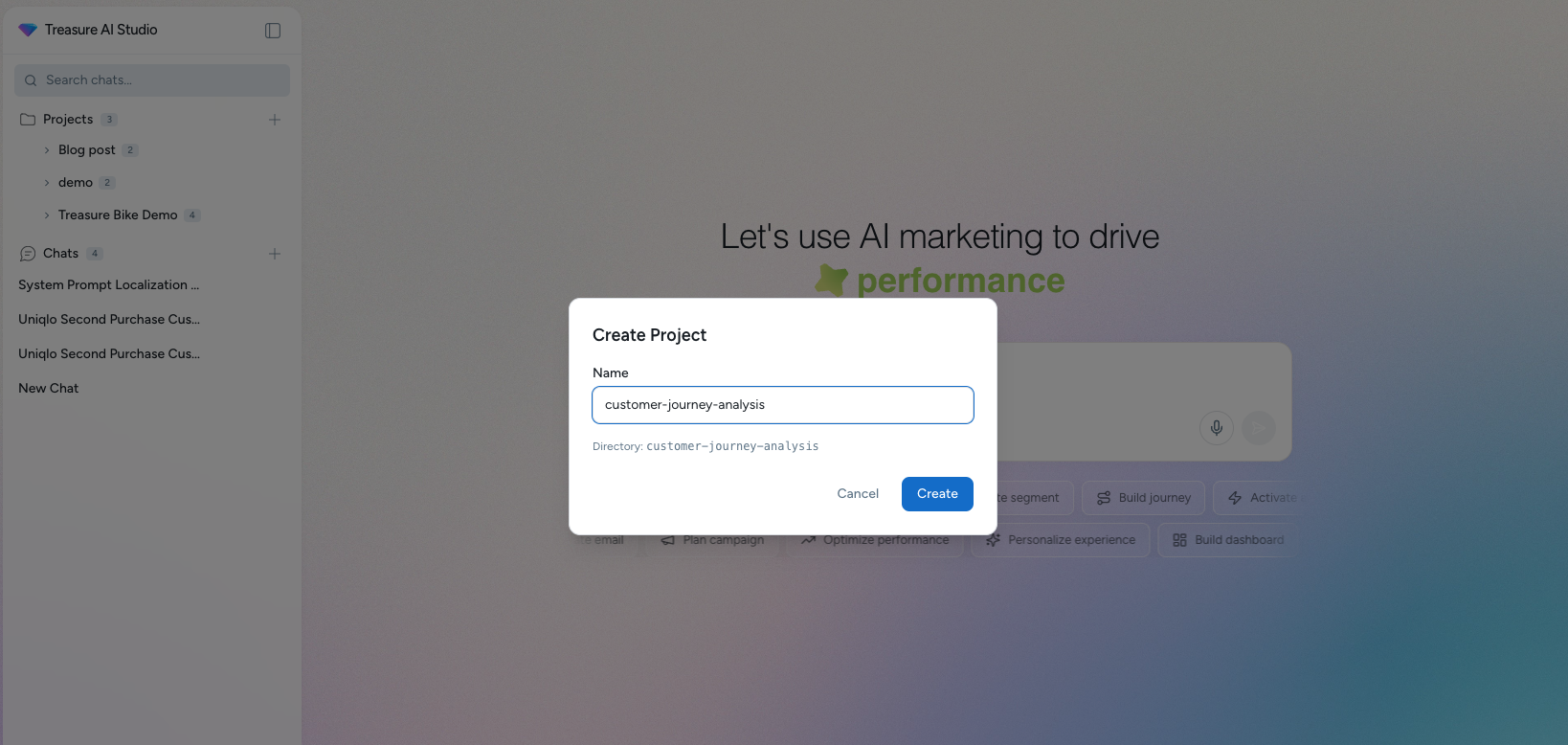
Treasure AI Studio Project機能セットアップガイド - 一貫したAI動作のためのコンテクスト維持
Treasure AI StudioのProject機能を使って、チャットセッション間で共通のコンテクストを維持し、一貫したAIエージェントの動作を実現し、構造化されたデータスキーマとビジネスルールによって出力の揺らぎを防ぐ方法を学びます。
Treasure AI Studioで実現する、セグメント分析からカスタマージャーニー作成までのワンストップ自動化
Audience Agentから進化したTreasure AI Studioで、プロジェクト機能を活用したコンテキスト共有と、AIエージェントによるカスタマージャーニー自動作成の実践例をご紹介します。

Treasure AIのエンジニアリングカルチャーは比類なき強さ
Treasure AIのスタッフソフトウェアエンジニアCarlo Luis Espinosaが、同社の最新のAIへの取り組みが、会社と自身のキャリアの双方にこれまでにない機会をもたらしている様子を語ります。
エンタープライズ向けにMLアルゴリズムをスケールさせる
Treasure AIのスタッフ機械学習/ソフトウェアエンジニアDavid Landupが、MLとソフトウェアの帽子を被り替える楽しさや、Treasure AIの「広大なエコシステム」をなぜこれほど楽しいと感じるのかを語ります。
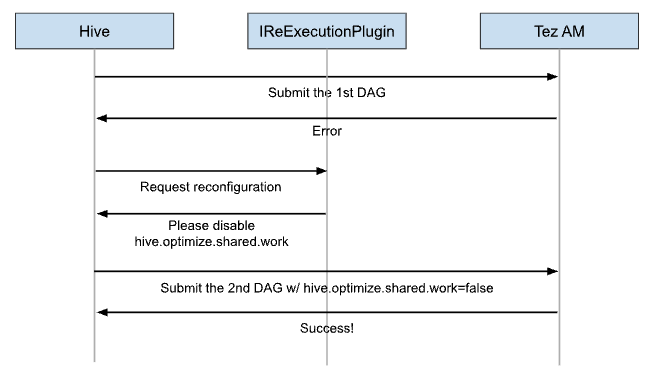
Leveraging Query ReExecution for Smooth Hive 4 Migration
How Apache Hive's Query ReExecution feature recovers failing queries and enables smooth migration to Hive 4.

Orchestrate dbt with Treasure Workflow Episode 2
Advanced dbt practices with Treasure Workflow including node selection, batch materialization, and data mesh.
Upcoming Evolution of Treasure Data Query Engines
Migration from Presto to Trino and upgrade from Hive 2 to Hive 4 with performance improvements.
Treasure AIでインポスター症候群を乗り越える
Treasure AIでData Clean Roomプロダクトに取り組むソフトウェアエンジニアTyler Welshが、Treasure AIがチームの学びと成長をどう支援しているか、そしてサービスの品質とパフォーマンスにどう投資しているかを語ります。

Journey to Containers in Core Services Worker Platform
Evolution of Worker Platform from stateful processes to container-based architecture.
Automatic Customer Segmentation with Machine Learning
Auto-Segmentation using K-Means clustering with feature prioritization and Shapley Values.
Testing Distributed Components of Storage Engine
Asynchronous test executor architecture using SQS, DynamoDB, and S3 for distributed storage testing.

Leveraging feedback is a skill!
Techniques for receiving and incorporating feedback effectively for career growth.
Orchestrate dbt with Treasure Workflow
Integration of dbt Core with Treasure Workflow including setup, containerization, and deployment.
The Zero Bug Policy
Fix important bugs immediately or close them — a practical bug management technique.
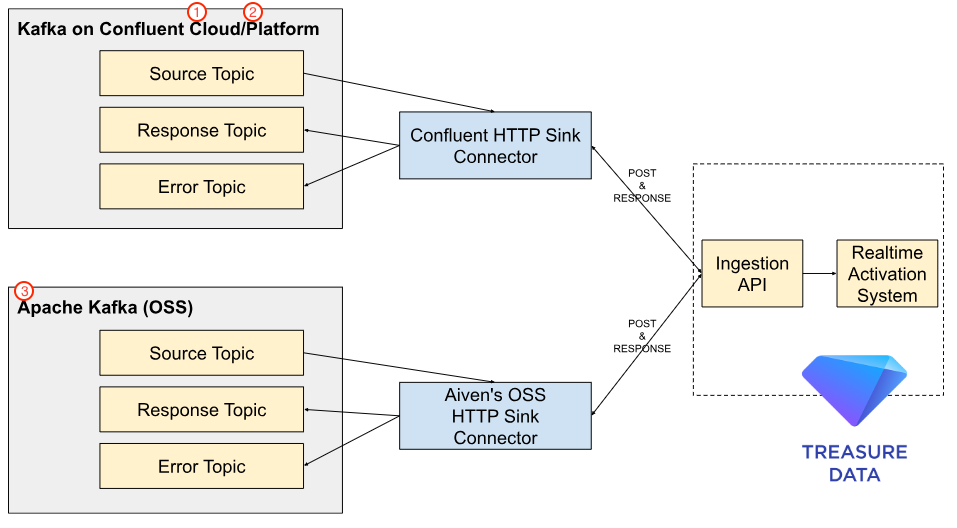
Integrating Kafka with Treasure Data
Leverage Kafka with HTTP Sink Connector to connect to the Treasure Data CDP.

Visual Studio Code extension for Treasure Data
Boost Your Data Analysis Workflow with TD Query Tool for VS Code.
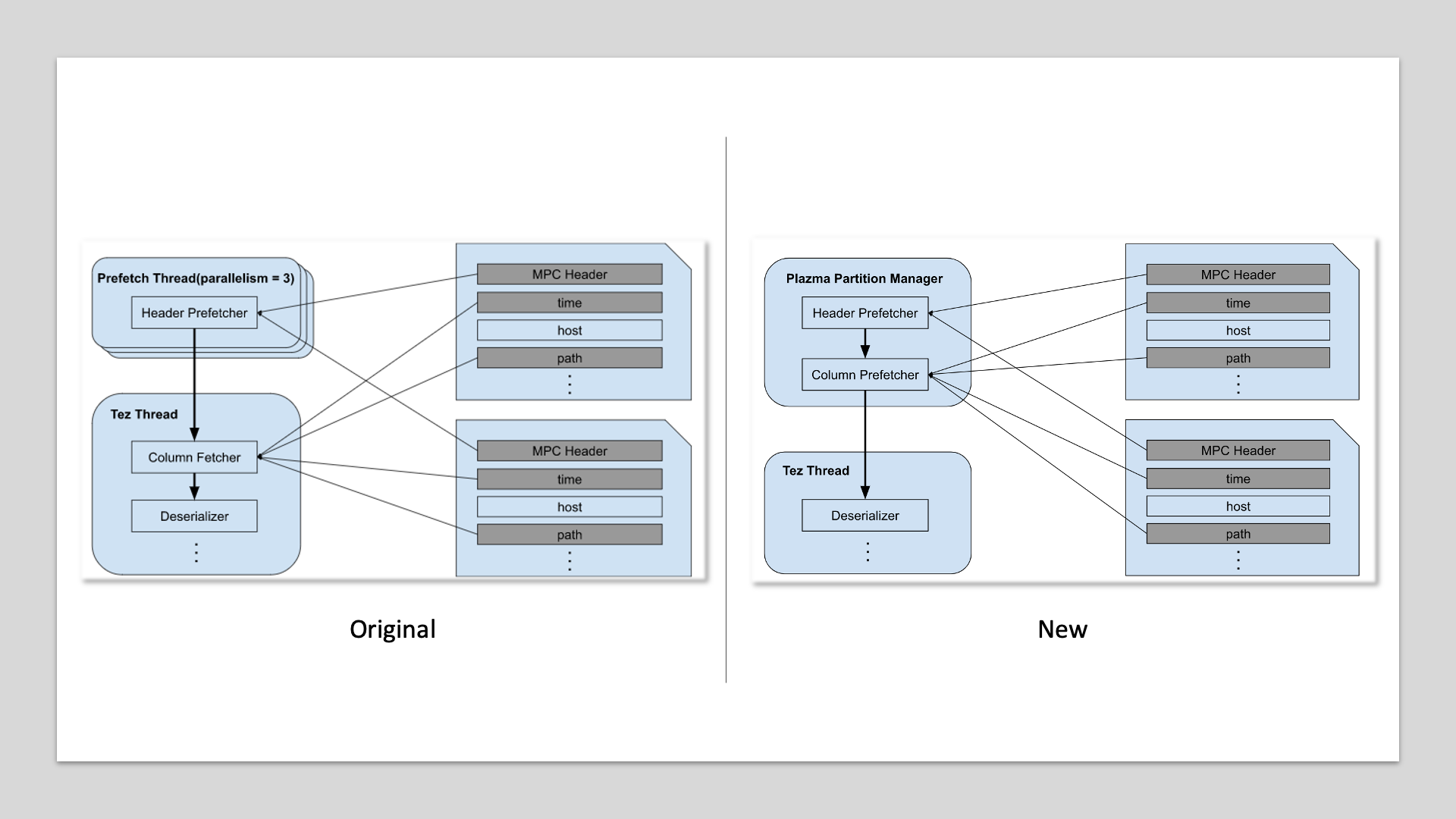
Hive Table scan optimization
20-30% performance improvements through parallelized S3 I/O optimization.

Continuous Deployment of Treasure Workflow with Azure DevOps
Repository setup, Azure Pipeline configuration, and deployment procedures for TD Workflow.
How to prepare simple test data for Hive and Presto
Techniques for preparing test data without creating test tables using single-row and multi-row queries.
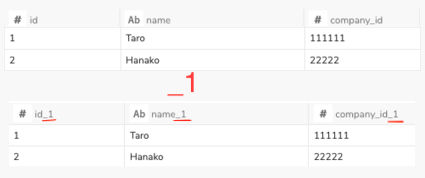
Debugging unexpected _1 column's on data connector import
Why unexpected _1 columns appear in data connector imports and how to fix them.
Embulk in TD, and in the future
History of Embulk in Treasure Data, technical challenges, and open-source strategy lessons.
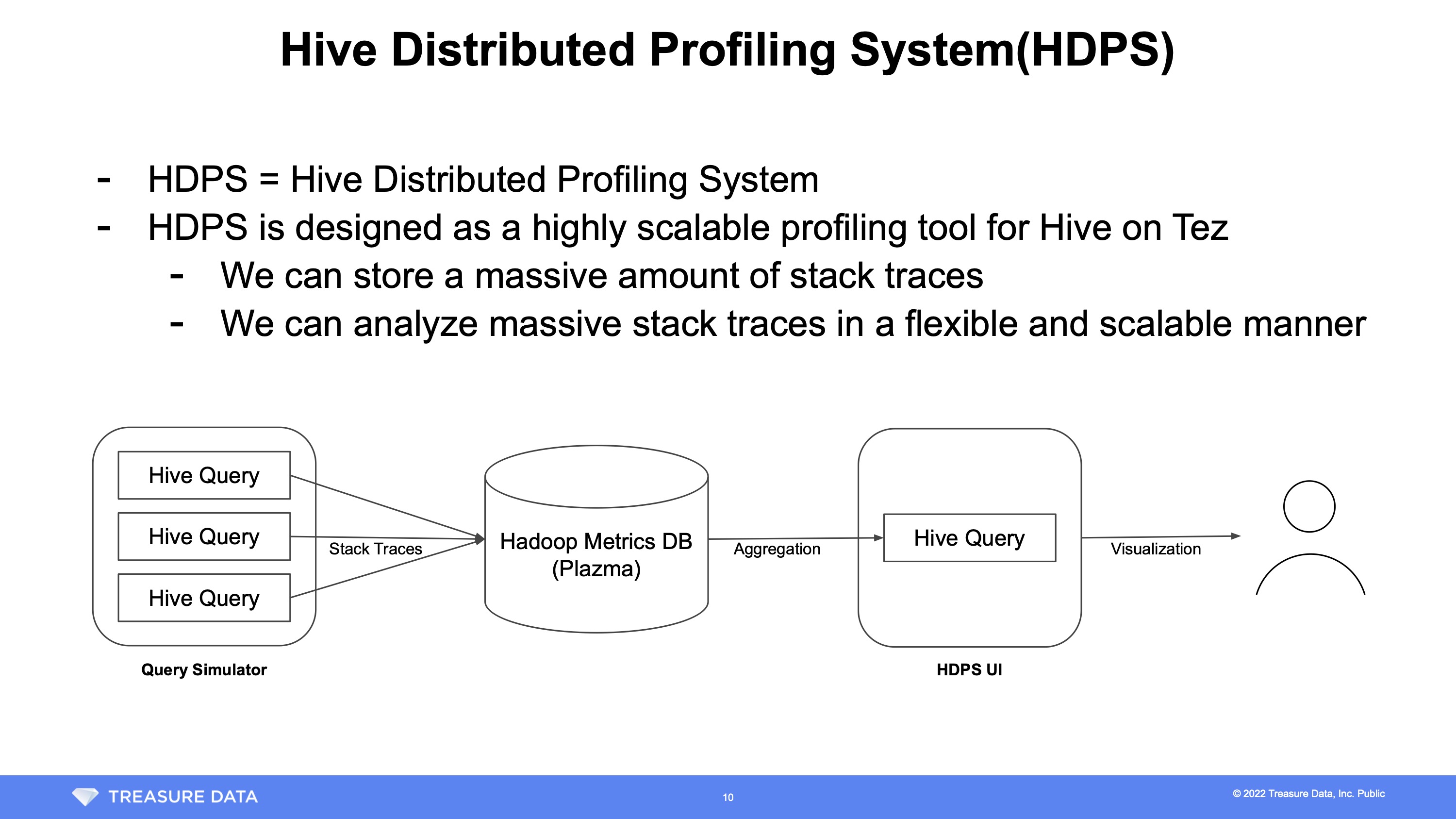
Implementing the Hive Distributed Profiling System
Using Java Flight Recorder and d3-flame-graph for distributed Hive performance analysis.

#TDTechTalk : 5 challenges in CDP
The first TD in-person meet-up in three years.
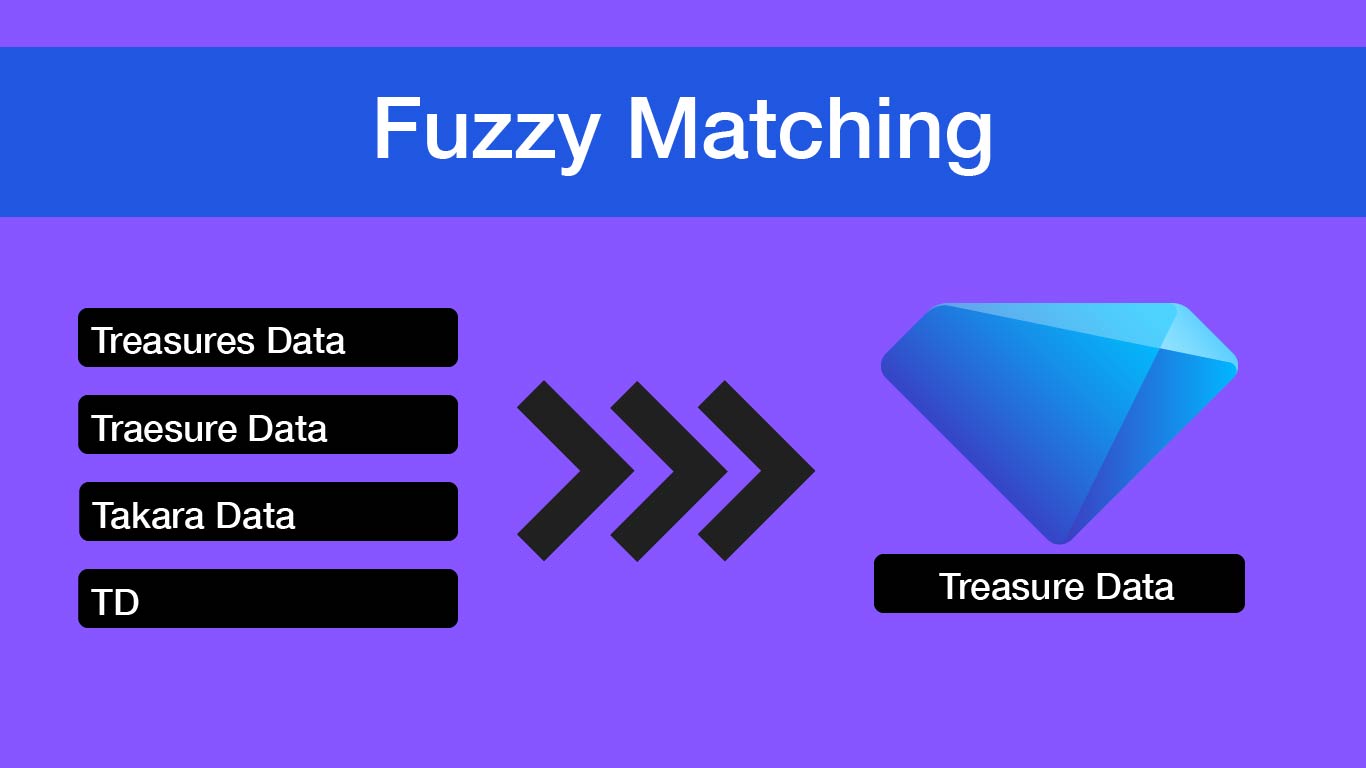
Fuzzy Matching
Fuzzy matching techniques using RLIKE, Levenshtein algorithm, and SOUNDEX with SQL examples.