Developer Blog
Technical articles, best practices, and engineering insights from the Treasure Data developer team.

Treasure AI Night Recap — Behind the Scenes of AI-Native Products
Recap of Treasure AI Night: the rebrand to Treasure AI, the Three-Layer Harness behind Treasure Work, and the Treasure AI Studio enterprise platform.
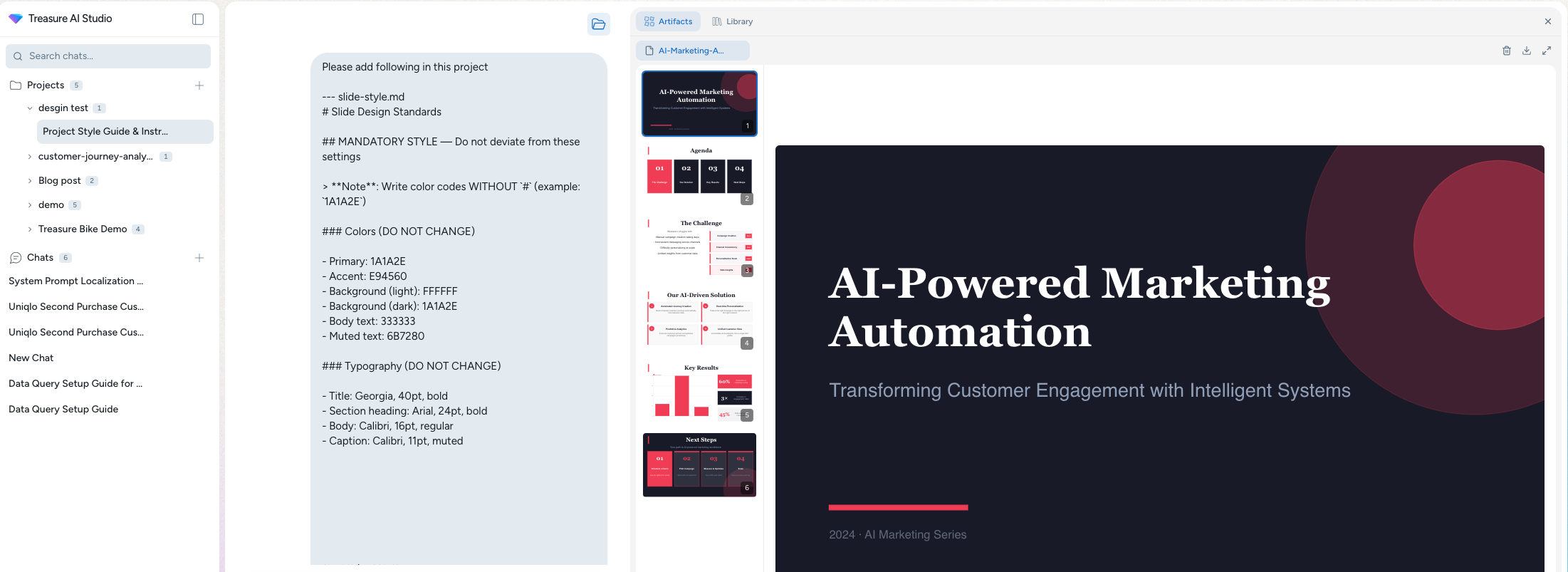
How to Lock Down AI-Generated Slide Design — The slide-style.md Approach
A practical method to ensure consistent slide design in Treasure AI Studio. Use slide-style.md as a configuration file to achieve uniform output across sessions.
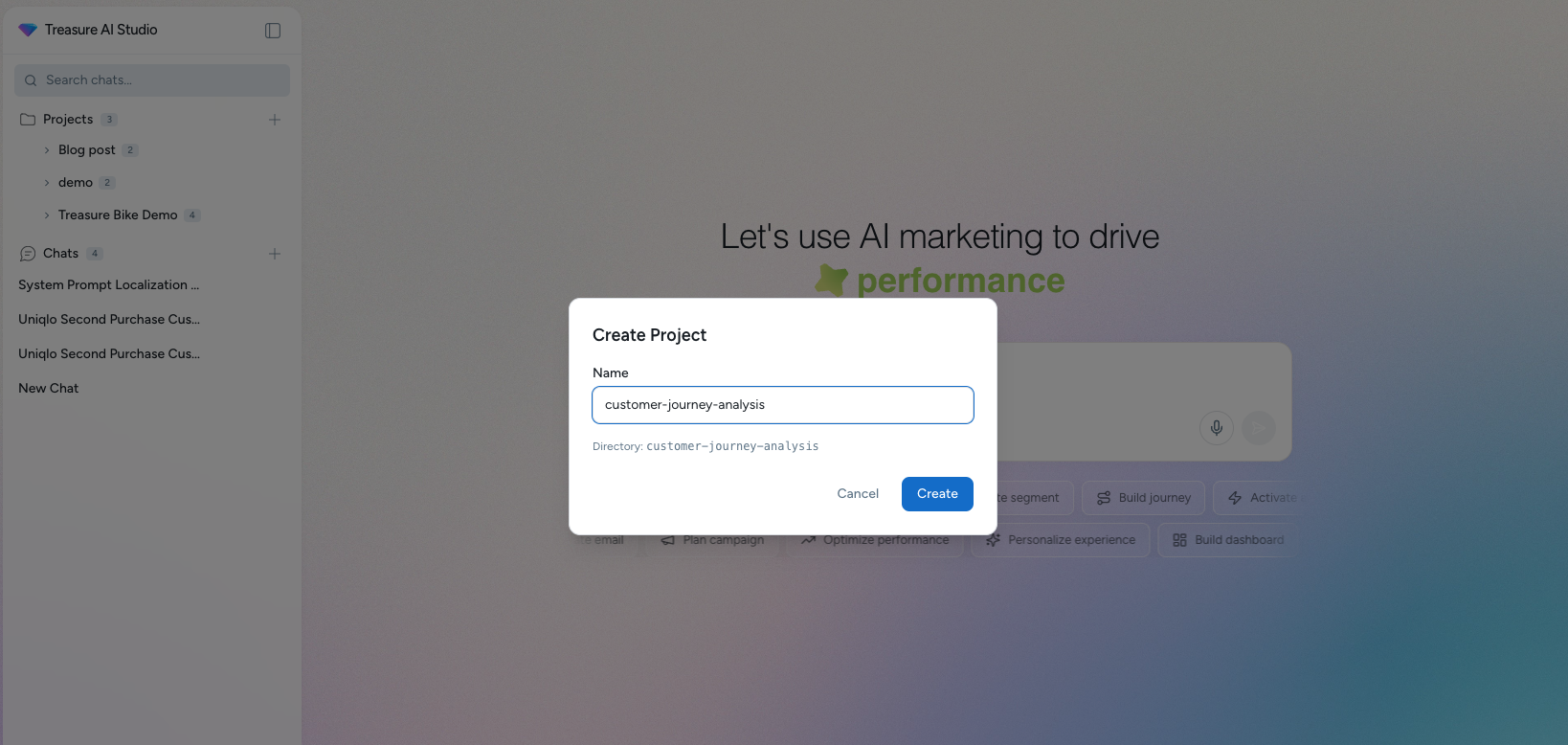
Treasure AI Studio Project Setup Guide - Maintaining Context for Consistent AI Behavior
Learn how to use the Project feature in Treasure AI Studio to maintain shared context across chat sessions and achieve consistent AI agent behavior.
From Segment Analysis to Customer Journey Creation - One-Stop Automation with Treasure AI Studio
Discover how Treasure AI Studio, evolved from Audience Agent, leverages project-based context sharing and enables automated customer journey creation through AI agents.

"The Engineering Culture is Unmatched" at Treasure AI
Carlo Luis Espinosa, a Staff Software Engineer at Treasure AI, shares how the company's latest AI initiatives are opening up unprecedented opportunities for both the company and his career.
Scaling ML Algorithms for Enterprise
David Landup, Staff Machine Learning/Software Engineer at Treasure AI, discusses how he enjoys switching hats between ML and software, and why he finds Treasure AI's "extensive ecosystem" so much fun.
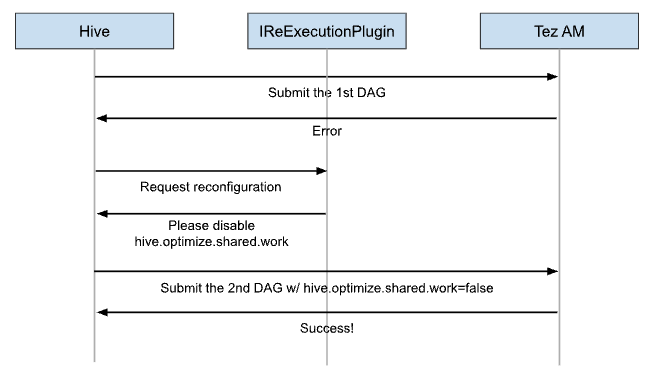
Leveraging Query ReExecution for Smooth Hive 4 Migration
How Apache Hive's Query ReExecution feature recovers failing queries and enables smooth migration to Hive 4.

Orchestrate dbt with Treasure Workflow Episode 2
Advanced dbt practices with Treasure Workflow including node selection, batch materialization, and data mesh.
Upcoming Evolution of Treasure Data Query Engines
Migration from Presto to Trino and upgrade from Hive 2 to Hive 4 with performance improvements.
Overcoming Imposter Syndrome at Treasure AI
Tyler Welsh, a software engineer at Treasure AI working on the Data Clean Room product, talks about how Treasure AI supports their team's learning and growth, and how they invest in the quality and performance of their services.

Journey to Containers in Core Services Worker Platform
Evolution of Worker Platform from stateful processes to container-based architecture.
Automatic Customer Segmentation with Machine Learning
Auto-Segmentation using K-Means clustering with feature prioritization and Shapley Values.
Testing Distributed Components of Storage Engine
Asynchronous test executor architecture using SQS, DynamoDB, and S3 for distributed storage testing.

Leveraging feedback is a skill!
Techniques for receiving and incorporating feedback effectively for career growth.
Orchestrate dbt with Treasure Workflow
Integration of dbt Core with Treasure Workflow including setup, containerization, and deployment.
The Zero Bug Policy
Fix important bugs immediately or close them — a practical bug management technique.
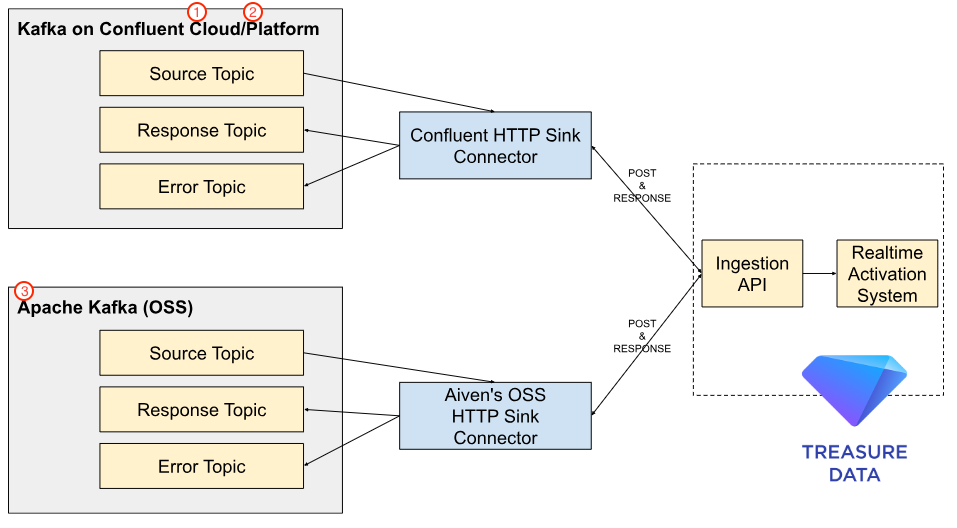
Integrating Kafka with Treasure Data
Leverage Kafka with HTTP Sink Connector to connect to the Treasure Data CDP.

Visual Studio Code extension for Treasure Data
Boost Your Data Analysis Workflow with TD Query Tool for VS Code.
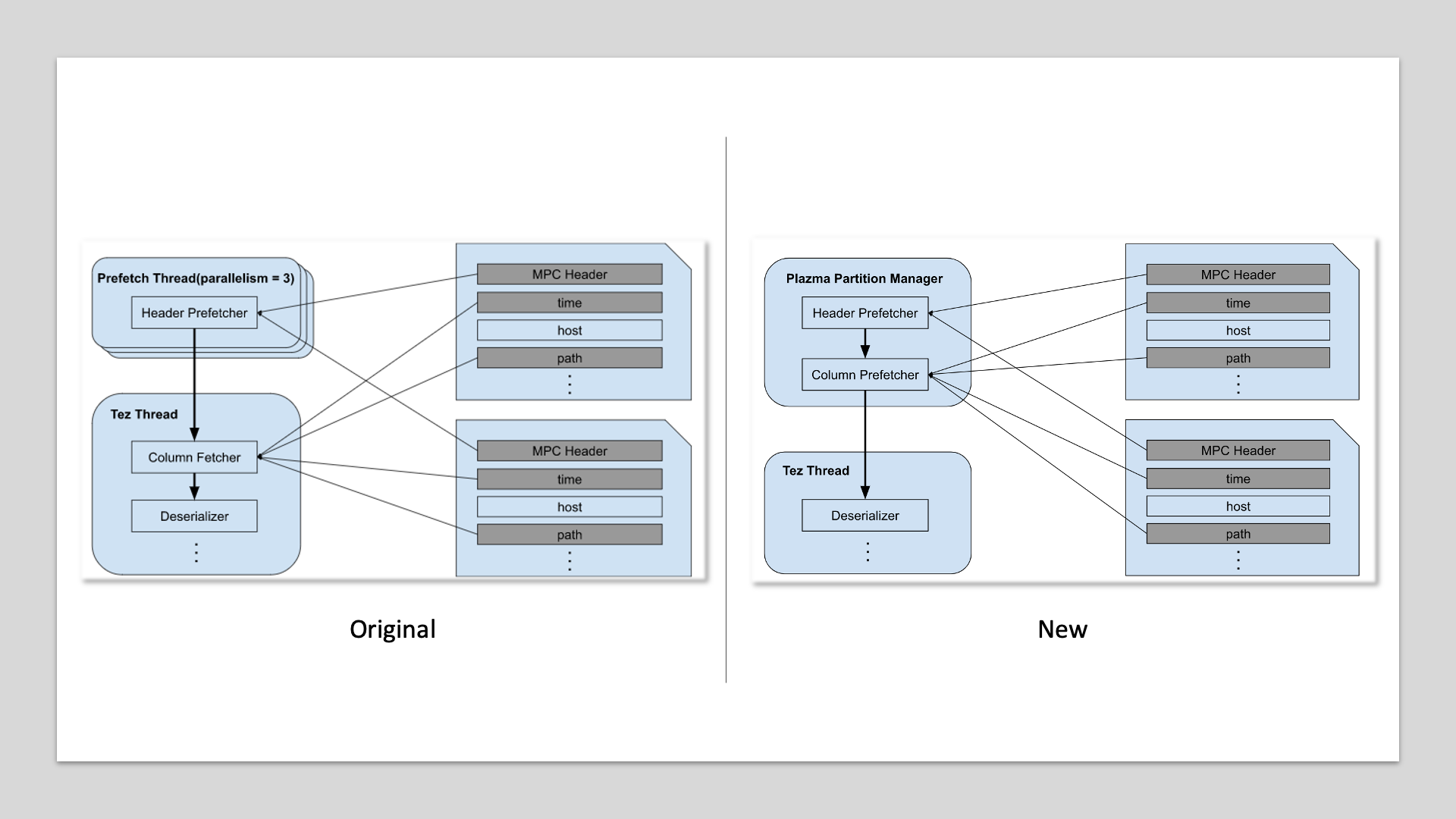
Hive Table scan optimization
20-30% performance improvements through parallelized S3 I/O optimization.

Continuous Deployment of Treasure Workflow with Azure DevOps
Repository setup, Azure Pipeline configuration, and deployment procedures for TD Workflow.
How to prepare simple test data for Hive and Presto
Techniques for preparing test data without creating test tables using single-row and multi-row queries.
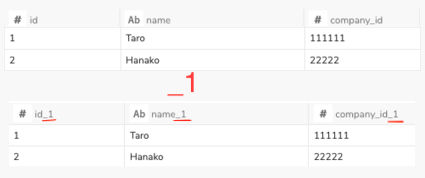
Debugging unexpected _1 column's on data connector import
Why unexpected _1 columns appear in data connector imports and how to fix them.
Embulk in TD, and in the future
History of Embulk in Treasure Data, technical challenges, and open-source strategy lessons.
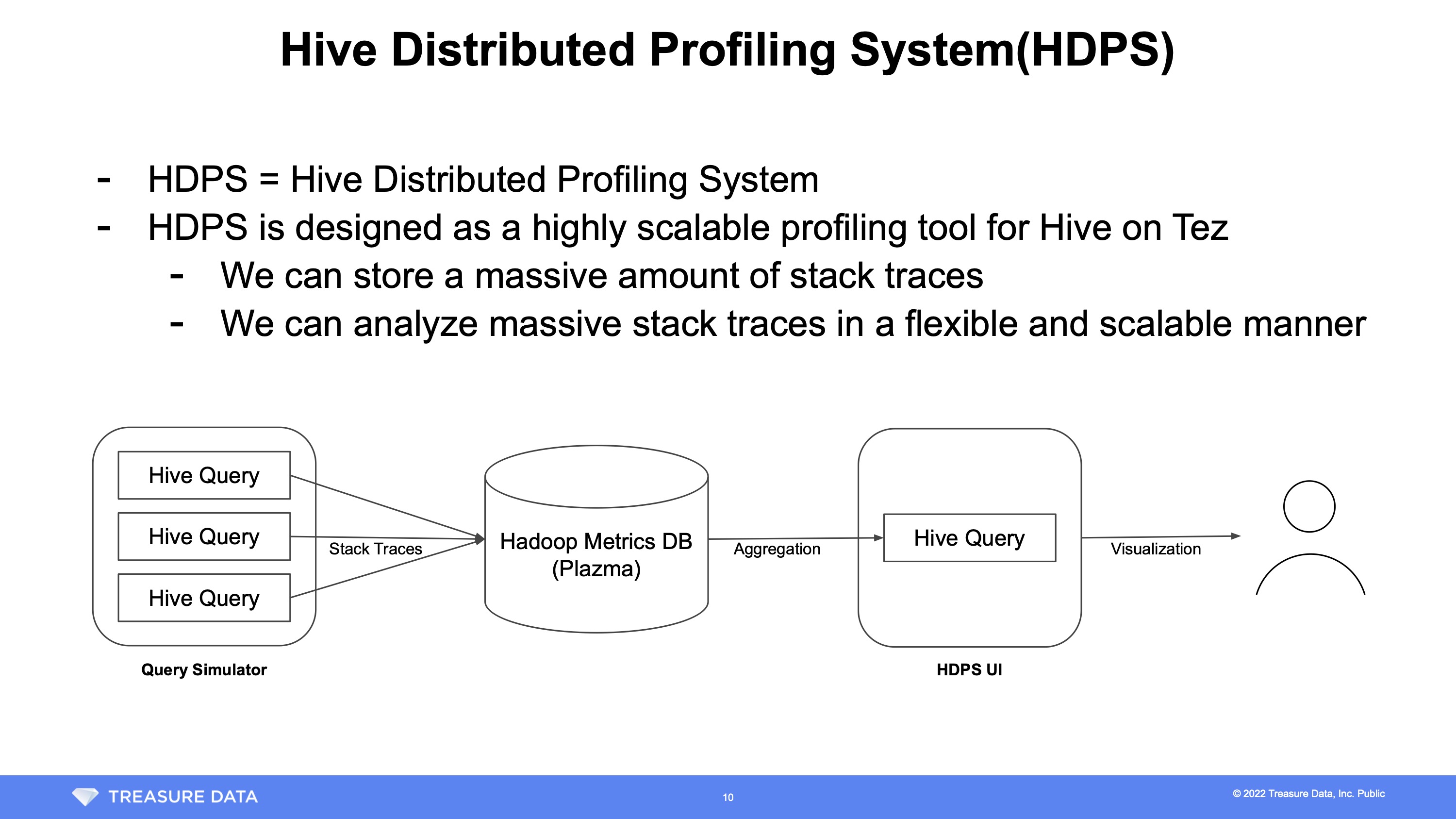
Implementing the Hive Distributed Profiling System
Using Java Flight Recorder and d3-flame-graph for distributed Hive performance analysis.

#TDTechTalk : 5 challenges in CDP
The first TD in-person meet-up in three years.
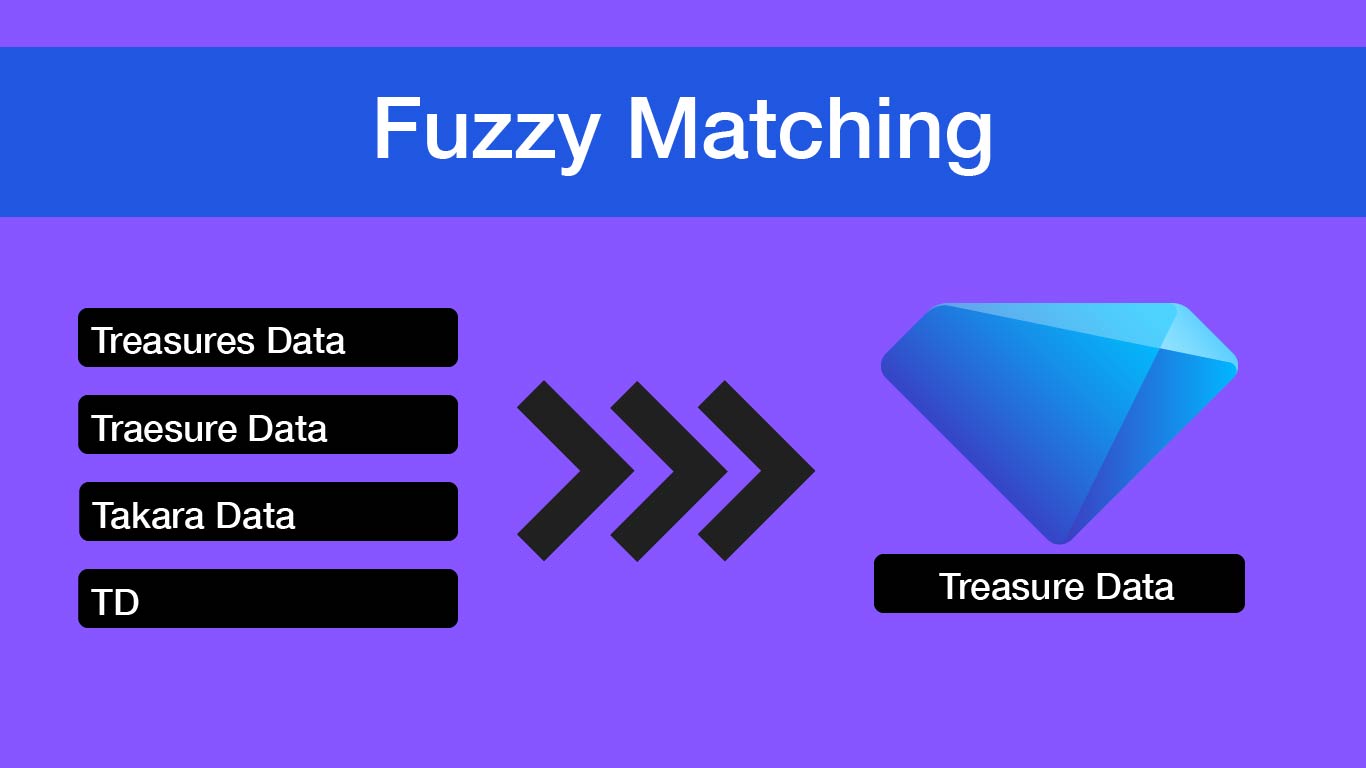
Fuzzy Matching
Fuzzy matching techniques using RLIKE, Levenshtein algorithm, and SOUNDEX with SQL examples.