バッチインポートでは、履歴データを一括で読み込んだり、増分データの定期収集をスケジュールできます。Treasure AIは以下のインポート方法をサポートしています。
Treasure コンソールからCSVまたはTSVファイルを直接アップロードできます。
Treasure コンソールを開きます。
Integrations Hub > Catalog に移動します。右上にアップロードオプションが表示されます。
Upload File を選択します。
ファイルをウィンドウにドラッグするか、参照して選択します。
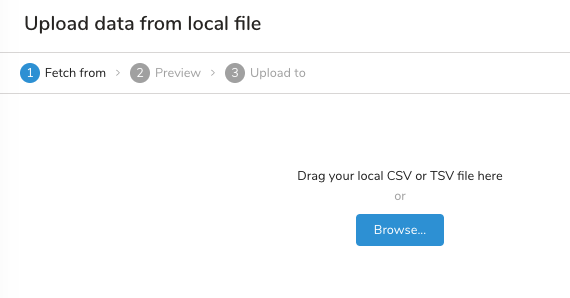
データをプレビューします。
オプションで Advanced Settings を選択し、ファイルのデコード、区切り文字、カラム名、データ型を設定します。
Treasure AI内の転送先データベースとテーブルを指定します。
オプションで、テーブルの既存データに追加するか置換するかを選択します。
オプションで、パーティションキーとして使用するタイムスタンプを指定します。
Upload を選択します。
Treasure コンソールからのCSV/TSVアップロードは200 MB未満である必要があります。
カタログからインポートインテグレーションを設定して、Treasure AIにデータをバルクロードできます。Treasure AIは、Webサイトトラッキング、モバイルアプリ、ソーシャルメディア、クラウドストレージ、データベースなど多数のコネクタを提供しています。
インテグレーションベースのインポートを設定するには:
- Treasure コンソールを開き、Integrations Hub > Catalog に移動します。
- 追加するデータソースタイプを選択します。
- データソースにアクセスするための認証情報を入力します。
- ソース設定(取得するデータ)を定義します。
- データをプレビューします(オプション)。
- 転送先データベースとテーブルを定義します。
- データ収集のスケジュールを設定します。
設定後、Integrations Hub > Sources からソースを管理できます。詳細はデータソースの新規作成を参照してください。
大規模なインポートには、Treasure AIがサポートするオープンソースのバルクデータローダー Embulk を使用します。Embulkは、データベース、ストレージ、ファイル形式、クラウドサービス間でデータを転送します。
- Bulk Data Importのインストール — EmbulkとTreasure AIプラグインのインストール
- Bulk Importインテグレーションオプション — サポートされるソースコネクタ
- Bulk Importでの環境変数の使用
インポート時に、パーサー、フィルター、デコーダーを適用して、Treasure AIに格納する前にデータを変換できます。
- パーサー — CSV、JSON、Avro、MessagePackなどのファイル形式を解釈します。パーサーを参照してください。
- フィルター — カラムの操作、JSONの展開、データマスキングなどを行います。フィルター関数についてを参照してください。
- デコーダー — パース前に圧縮またはエンコードされたファイルをデコードします。File Decoder Functionを参照してください。
上級ユーザーはTD Toolbeltコマンドラインインターフェースを使用してデータをインポートできます: