マスターセグメントは、マスターテーブル、属性テーブル、および行動テーブルを統合するワークフローを生成します。
ワークフローは計算負荷の高いプロセスになる傾向があるため、Treasure Data は、現在実行している他のジョブやプロセスとの計算リソースの競合を回避する方法を提供しています。
マスターセグメントでは、使用する処理エンジンのタイプと関連するリソースプールを指定できます。例:
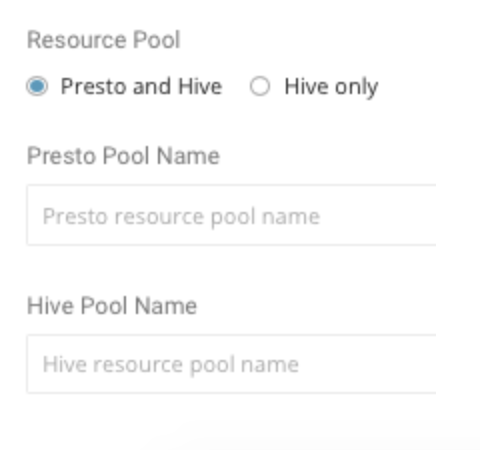
次を選択できます:
Trino と Hive
Hive のみ
選択により、マスターセグメント作成に使用される処理エンジンが決まります。
一般的には Hive のみを推奨します。これは、大規模な結合向けに設計されており、堅牢性で知られていますが、Trino と Hive は小規模なデータセットの場合、より高速に実行される可能性があります。
Trino と Hive を選択すると、ほとんどのジョブは Hive で発行されますが、drop/create table 操作用の一部の Trino クエリが生成されます。
(注:Hive のみはほとんどのジョブを Hive で発行しますが、drop/create table 操作用の一部の Trino クエリを生成します)
各エンジンに使用するリソースプールを指定することもできます。リソースプールを指定すると、追加の計算リソース制御が可能になります。